
Common Voice ora parla Italiano, ti va di donare la tua voce?
Cos’è Common Voice
Common Voice (https://voice.mozilla.org) è un progetto di crowdfunding di Mozilla. Non quello classico pensato per raccogliere soldi, bensì dati testuali e vocali basati su lingue specifiche, nato dal progetto Open Source di riconoscimento vocale DeepSpeech (https://github.com/mozilla/DeepSpeech) che funziona grazie alla tecnologia di Machine Learning, imparando a riconoscere le lingue tramite parole e pronunce.
Il sito di Common Voice era già stato localizzato in italiano dalla nostra comunità qualche mese fa, ma mancava il supporto alla lingua della nostra nazione, ora finalmente disponibile. Per poter quindi permettere a Common Voice di progredire, c’è bisogno di quel nutrimento composto dalla partecipazione di volontari che leggono del testo (o che revisionano le registrazioni già eseguite) in una specifica lingua. Con centinaia di letture della stessa frase, il software si occuperà di individuare le somiglianze, è qui che interviene il Machine Learning, il quale isolerà le caratteristiche simili nelle frasi registrate da più persone con accenti diversi, tono, velocità e pronuncia.
Tali somiglianze verranno in seguito aggregate dal software in un modello: uno schema di riconoscimento dei dati (vocali) che gli permetterà di riconoscere frasi mai sentite prima. Ovviamente, il modello si basa su una moltitudine di frasi contenenti parole appartenenti anche ad altri vocabolari (per esempio “feedback”, usato anche nella nostra lingua seppur originario di quella inglese), sigle (che noi italiani pronunciamo spesso in diverse maniere), parole con lettere accentate e non solo. Il modello è il prodotto di questo motore (e progetto) che viene reso poi pubblico, corredato di tutte le registrazioni audio (https://voice.mozilla.org/it/data) fornite sotto libera licenza.

Il supporto dell’Italiano
Puoi facilmente immaginare quanto queste frasi, lette o revisionate dai partecipanti su base volontaria, abbiano richiesto in termini di tempo e lavoro alla nostra comunità. Abbiamo partecipato allo Sprint (https://voice-sprint.mozilla.community) organizzato da Mozilla nel mese di maggio, ma il materiale non era sufficiente per sbloccare la lingua sul portale. Questo perché tutte le frasi devono essere di pubblico dominio, sotto licenza Creative Commons Zero o messe a disposizione con il permesso degli autori, fino a raggiungere un minimo di 5000 per poter sbloccare la lingua. Abbiamo voluto sfidare i nostri limiti e impegnarci, fino a raggiungere le oltre 7700 frasi odierne. Ciascuna di queste è stata estratta da diverse fonti per poter aggregare svariate tipologie di testo:
- Manualistica di traduzione (per esempio https://mozillaitalia.gitbooks.io/l10n-guide/it/);
- Manualistica di informatica (per esempio il materiale del Team per la Trasformazione digitale, o nostri articoli precedentemente pubblicati nei nostri siti web e Social);
- Testi religiosi (discorsi dei Papi del ‘900);
- Libri gialli (di pubblico dominio);
- Racconti Fantasy/Sci-Fi;
- Tesine delle Scuole Superiori;
- Temi scolastici;
- Modi di dire e scioglilingua;
- Resoconti di eventi (scritti dai nostri volontari);
- Canti popolari;
- Materiale sportivo;
- Estratti di messaggi scambiati via chat;
- Documenti di stampo manageriale (come i verbali di riunioni).
Tutto ciò è stato successivamente revisionato per limitare e correggere quanti più errori grammaticali possibili, eliminare doppioni e accorciare le frasi (poiché il portale impone un tetto massimo per la lunghezza delle registrazioni audio), quindi rimuovere ogni possibile riferimento a dati privati.
Siamo certi di aver tralasciato involontariamente degli errori, e per questo ti invitiamo a segnalarli sul nostro forum (https://forum.mozillaitalia.org/index.php?topic=71027.msg492854), oppure creando una pull request sul nostro fork GitHub (https://github.com/MozillaItalia/voice-web/blob/ita-review/server/data/it/frasi.txt). Al momento non stiamo raccogliendo altre frasi ma preferiamo focalizzarci sul miglioramento del materiale già esistente, per evitare di alzare la soglia di complessità della sua gestione.
Perché partecipare
Realizzare un modello della lingua italiana che sia libero da qualunque licenza commerciale, richiesta di internet e affidato a terzi, ci permette di mantenere sicurezza, privacy ed estensibilità senza limiti, per questo motivo Mozilla ha realizzato il progetto Common Voice.
Il dataset della lingua inglese è stato già reso disponibile (modello incluso), e contiene oltre 1000 ore di registrazione fatte da 20000 volontari diversi (https://blog.mozilla.org/blog/2017/11/29/announcing-the-initial-release-of-mozillas-open-source-speech-recognition-model-and-voice-dataset). Questo modello è liberamente utilizzabile per progetti educativi o personali, e ha un quantitativo di errori inferiore al 10%, per approfondire questo aspetto ti invitiamo a leggere l’articolo ufficiale all’indirizzo https://hacks.mozilla.org/2017/11/a-journey-to-10-word-error-rate/.
Common Voice ti dà la possibilità di integrare questi dataset con altri progetti Open Source, un esempio è https://mycroft.ai (installabile sul proprio computer o utilizzabile tramite dispositivo ufficiale) per ottenere un Alexa libero sfruttando la tecnologia di Mozilla, già integrata di base. In alternativa potremmo citare https://xaero.app, per realizzare correttori grammaticali basati sul modello ottenuto da Common Voice e utile per effettuare controlli di testo ancora più accurati, o ancora dei progetti di Text-to_speech già liberamente ottenibili da GitHub: https://github.com/mozilla/tts.
Altra buona opportunità per gli sviluppatori è il poter sfruttare la raccolte di frasi di pubblico dominio che può essere utilizzata anche per altre tipologie di progetti Machine Learning, il tutto accessibile già da https://github.com/mozilla/voice-web/tree/master/server/data.
Come partecipare
Per partecipare non è necessario lasciare alcun dato personale. Registrando però un account sul sito https://voice.mozilla.org/it/languages, sarà possibile tracciare quanto è stato fatto fino a quel momento, diversamente si rimarrà anonimi. Sfruttando la nuova interfaccia del portale da poco rilasciata, si potrà accedere ai due tipi di attività (disponibili anche da mobile), inserimento o revisione.
Per partecipare non è necessario installare alcun software, basterà il browser e l’abilitazione all’uso del microfono (permesso che verrà richiesto direttamente dal sito web visitato).
Parla
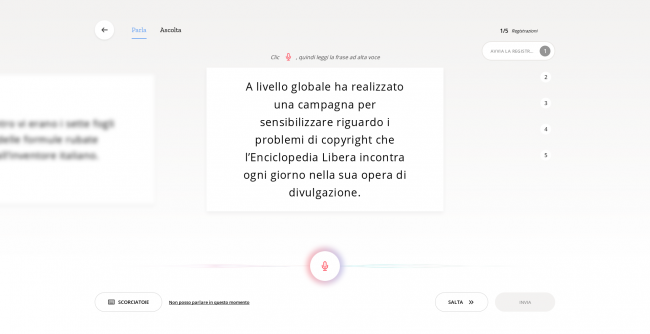
Tramite la scheda “Parla” sarà possibile registrare un file audio leggendo il testo visualizzato. Sarà possibile riascoltare la registrazione e approvarla prima di confermarne il caricamento.
Ascolta
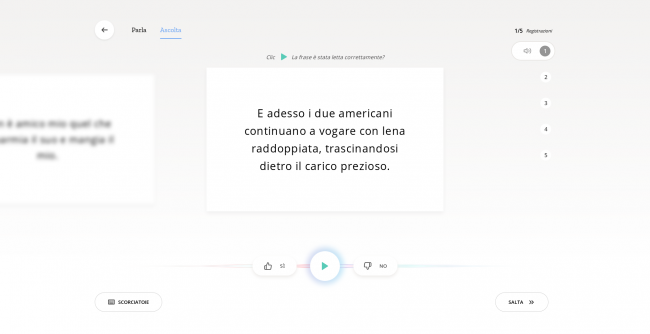
Tramite la scheda “Ascolta” sarà possibile ascoltare le registrazioni fatte da altri utenti, così da approvarle o rifiutarle, quest’ultimo caso è utile nell’eventualità il termine (o l’intera frase) non venga detta in maniera corretta, oppure se sia stata pronunciata troppo velocemente. Si tratta di un’attività ideale da portare a termine quando si è impossibilitati a parlare ma non ad ascoltare (magari durante una visita in biblioteca, con le cuffie sulle orecchie).
Scorciatoie
Alcune scorciatoie da tastiera ti permetteranno di muoverti nell’interfaccia più rapidamente. premi P per mettere in pausa (o riprendere l’ascolto) o S per saltare alla successiva registrazione.
Quando sarà disponibile il modello Italiano?
Il piano di Mozilla è di rilasciare i modelli di ogni lingua intorno al termine dell’anno (Dicembre), ma questo sarà possibile solo se saranno state effettuare tante registrazioni grazie alla partecipazioni di altrettanti volontari. La qualità del riconoscimento vocale sta a noi!
Voglio promuovere il progetto, come posso farlo?
Fantastico! Se sei utilizzatore di , vieni a conoscere la comunità su https://t.me/mozItaHUB, entra quindi nel gruppo “Voglio diventare un volontario” per chiedere maggiori informazioni. Troverai membri della comunità italiana che potranno rispondere alle tue domande e fornirti idee per promuovere il progetto.
Se invece preferisci scambiare quattro chiacchiere dal vivo, ti invitiamo al prossimo evento a cui prenderemo parte, l’Italian Hacker Camp (https://www.ihc.camp). Troverai lì il nostro gazebo, potrai partecipare ai diversi talk organizzati e conoscere alcuni dei volontari presenti. Stiamo ancora definendo i dettagli, ma proveremo a premiare in quella sede tutti coloro che porteranno a termine una (qualitativamente e quantitativamente) alta attività su Common Voice (ma non solo), per te potrebbe esserci una nostra spilla, una maglietta, un adesivo (e tanti altri gadget).
Grazie
Non resta quindi che ringraziare (in ordine sparso) tutti coloro che hanno partecipato alle varie fasi del progetto, quelle che ci hanno portato al risultato di oggi, sperando di non dimenticare nessuno: Edoardo, Giorgio, Simone, Saverio, Daniele, Irene, Giovanni, Sara, Francesco, Stefania e i tanti altri, anche omonimi, che pur non contribuendo in maniera diretta, ci hanno spronato a dare il meglio per raggiungere l’obiettivo.
Testo: Daniele Scasciafratte | Revisione: Giovanni Francesco Solone
